
Building Points on Ceramic - an Example and Learnings
We built a Web3 points application on Ceramic to explore the design considerations a successful system requires.


We've made the case in a recent blog post that web3 point systems align the incentives of platforms and their users, acting as reputation systems that allow participants to draw inferences between who's creating value and who's likely to receive rewards for their actions. More importantly, these systems help participants understand what user interactions matter to applications using points. And while points often manifest as objects referred to by different names (badges and attestations, for example), there's a commonality across these implementations relevant to their verifiability.
Why Points and Ceramic?
Points data requires properties allowing consumers of points (traditionally the same applications issuing them) to trust their provenance and lineage. This is unsurprisingly why most Web3 points systems today are built on centralized rails - not only is a simple Postgres instance easy to spin up, but the only data corruption vulnerability would result from poor code or security practices.
For readers familiar with Ceramic's composability value proposition, it's likely obvious why we view web3 point systems (and reputation systems more broadly) as ideal Ceramic use cases. Not only does Ceramic offer rich query capabilities, data provenance and verifiability promises, and performance-related guarantees, but both end users and applications benefit from portable activity. We foresee an ecosystem where end users can leverage the identity they've aggregated from one application across many others. In turn, applications can start building on user reputation data from day one.
To put this into practice, we built a scavenger hunt application for EthDenver '24 that allowed participants to collect points based on in-person event attendance.
A Scavenger Hunt for Points
Ceramic was officially involved in 8 or so in-person engagements this year at EthDenver, some of which were cosponsored events (such as Proof of Data and Open Data Day), while others were cross-collaborations between Ceramic and our partners (for example, driving participants to check in at official partner booths at the official EthDenver conference location). The idea was simple - participants would collect points for checking in at these events, and based on different thresholds or interpretations of participant point data (for example, participants with the most event check-ins) would be eligible for prizes.
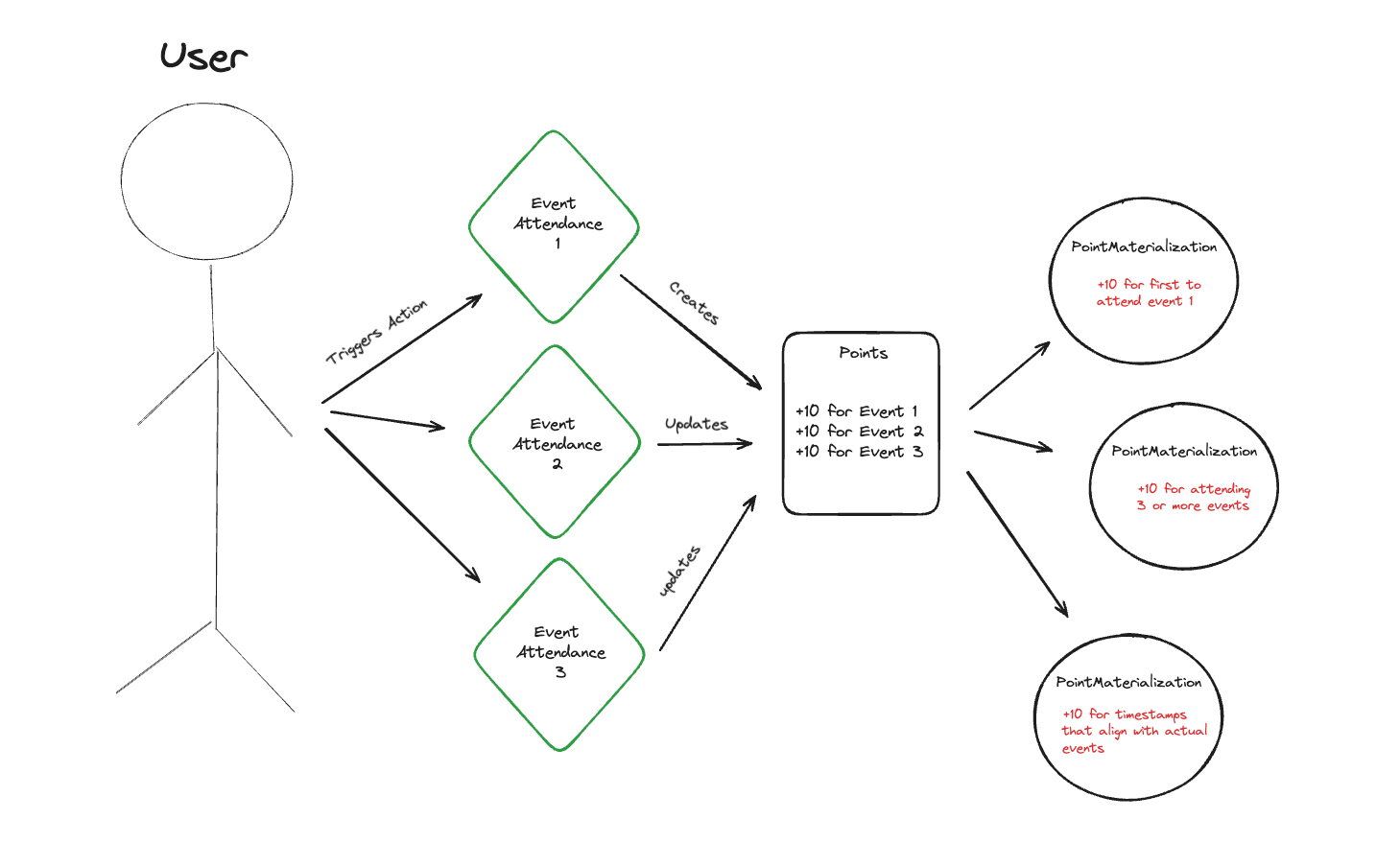
To make this happen, we ideated on various patterns of data control and schema design that presented the best balance of trade-offs for this use case. In simple terms, we needed to:
- Track event attendance by creating or updating abstractions of that activity in Ceramic
- Provide a crypto-native means for participants to self-identify to leverage Ceramic-native scalar types
- Secure the application against potential spoofing attempts
- Collect enough information necessary to perform creative computation on verifiable point data
We were also presented with several considerations. For example, should we go through the effort to emulate a user-centric data control design whereby we implement a pattern that requires additional server-side verification and signed data to allow the end user to control their Ceramic point data? Or what's the right balance of data we should collect to enable interesting interpretations (or PointMaterializations) to be made as a result of computing over points?
Architecting Document Control
Before we jump in, reading our blog post on Data Control Patterns in Decentralized Storage would help provide useful context. As for the problem at hand, two options stand out as the most obvious ways to build a verifiable points system on open data rails:
- Reconstruct the approach that would be taken on traditional rails (the application is the author and controller of all points data they generate). This makes the data easy to verify externally based on the Ceramic document controller (which will always be the same), and data consumers wouldn't have to worry about end users attempting to modify stream data in their favor
- Allow the end users to control their points data on Ceramic. In this environment, we'd need a flow that would be able to validate the existing data had been "approved" by us by verifying a signed payload, then update the data and sign it again before having the user save the update to their Ceramic document, thus ensuring the data is tamper-evident
You might've guessed that the second option is higher-touch. At the same time, a future iteration of this system might want to involve a data marketplace that allows users to sell their points data, requiring users to control their data and its access control conditions. For this reason and many others, we went with #2. We'll discuss how we executed this in the sections below.
What Data Models Did We Use?
When we first started building the scavenger hunt application the SET accountRelation schema option had not yet been released in ComposeDB (important to note due to the high likelihood we would've used it). Keep that in mind as we overview some of the APIs we built to check if existing model instances had been created (later in this article).
In discussing internally how points data manifests, we decided to mirror a flow that looked like trigger -> point issuance -> point materialization. This means that attending an event triggers issuing point data related to that action. In response, that issuance event might materialize as an interpretation of the weight and context of those points (which could be created by both the application that issued the points and any other entity listening in on a user's point activity).
As a result, our ComposeDB schemas ended up like this:
type PointClaims
@createModel(accountRelation: LIST, description: "A point claim model")
@createIndex(fields: [{ path: ["issuer"] }])
{
holder: DID! @documentAccount
issuer: DID! @accountReference
issuer_verification: String! @string(maxLength: 100000)
data: [Data!]! @list(maxLength: 100000)
}
type Data {
value: Int!
timestamp: DateTime!
context: String @string(maxLength: 1000000)
refId: StreamID
}
type PointMaterializations
@createModel(
accountRelation: LIST
description: "A point materialization model"
)
@createIndex(fields: [{ path: ["recipient"] }]) {
issuer: DID! @documentAccount
recipient: DID! @accountReference
context: String @string(maxLength: 1000000)
value: Int!
pointClaimsId: StreamID! @documentReference(model: "PointClaims")
pointClaim: PointClaims! @relationDocument(property: "pointClaimsId")
}To provide more context, we built the application to create a new PointClaims instance if one did not already exist for that user, and update the existing PointClaims instance if one already existed (and, in doing so, append an instance of Data to the "data" field). I mentioned above that the SET accountRelation option would've likely come in handy. Since we were hoping to maintain a unique list of PointClaims that only had 1 instance for each user (where the issuer represents the DID of our application), SET would've likely been the preferred way to go to make our lives easier.
You'll also notice that an optional field called "refId" that takes in a StreamID value exists in the Data embedded type. The idea here was that issuing points might be in response to the creation of a Ceramic document, in which case we might want to store a reference pointer to that document. For our scavenger hunt example, this was the case - points were issued in recognition of event attendance represented as individual Ceramic documents:
type EthDenverAttendance
@createModel(
accountRelation: LIST
description: "An attendance claim at an EthDenver event"
)
@createIndex(fields: [{ path: ["recipient"] }])
@createIndex(fields: [{ path: ["event"] }])
@createIndex(fields: [{ path: ["latitude"] }])
@createIndex(fields: [{ path: ["longitude"] }])
@createIndex(fields: [{ path: ["timestamp"] }])
@createIndex(fields: [{ path: ["issuer"] }]) {
controller: DID! @documentAccount
issuer: DID! @accountReference
recipient: String! @string(minLength: 42, maxLength: 42)
event: String! @string(maxLength: 100)
latitude: Float
longitude: Float
timestamp: DateTime!
jwt: String! @string(maxLength: 100000)
}Finally, take a look at the "issuer_verification" field in PointClaims and "jwt" field in EthDenverAttendance. Both fields were allocated to store the data our application verified + signed, represented as a base64-encoded string of a JSON web signature. For PointClaims, this entailed just the values within the "data" array (involving a verification, updating, and resigning process each time new point data needed to be appended).
Issuing Points - Data Flow
For the remainder of the article, feel free to follow along in the following public code:
https://github.com/ceramicstudio/fluence-demoYou'll notice two environment variables (SECRET_KEY and STRING) scoped only for server-side access, the first of which is meant to contain our secret 64-character seed from which we'll instantiate our application's DID (to be used for filtering PointClaims instances for documents where our application's DID is the issuer, as well as for verifying and signing our tamper-evident fields). To explain STRING, it might be helpful at this point if I dive a bit deeper into what we built to support the user flow.
Private PostgreSQL Instance (for Whitelisted Codes)
You'll notice that a findEvent method is called first in the useEffect lifecycle hook within the main component rendered on our post-login screen, which subsequently calls a /api/find route (which uses our STRING environment variable to connect to our PostgreSQL client). For this application, we needed to quickly build a pattern where we were able to both issue and verify codes corresponding to each in-person event that had been generated beforehand. This ties back to our planned in-person flow:
- Participant scans a QR code or taps an NFC disc that contains the URL of our application + a parameterized whitelisted code that hasn't yet been used
- The application checks the database to ensure the code hasn't yet been used
While in theory this part could've been built on Ceramic with an added layer of encryption, it was easier to stand this up quickly with a private Postgres instance.
Determining Participant Eligibility
If the call to /api/find determines that the code has not been used, findEvent then calls a createEligibility method, passing in the name of the event as the input variable. Notice that the first thing we do is call a getDID method, which calls a /api/checkdid server route that uses our SECRET_KEY variable to instantiate a DID and send us back the did:key identifier.
This is the second check our application performs to prevent cheating, whereby we query ComposeDB for EthDenverAttendance instances, filtering for documents where the signed-in user is the controller, where the event is the string passed into createEligibility, and where our application is the issuer (as evidenced by the DID).
Finally, if no matching document exists, we determine that the participant is eligible to create a badge.
Generating Points Data
While there's plenty to discuss related to generating and validating badge data, given that the pattern is quite similar when issuing points, I'll focus on that flow. The important thing to know here is that within both our createBadge and createFinal methods found in the same component mentioned above call an issuePoint method if a badge was successfully created by the user, passing in the corresponding value, context, and name of the event corresponding to that issuance.
What happens next is a result of our decision to allow the end user to control their points-related data, such that we:
- Call an API route to access our application's DID
- Call yet another
/api/issueroute, where we- Query
PointClaimsto see if one already exists or not for the end user where our application is also the issuer
- Query
const authenticateDID = async (seed: string) => {
const key = fromString(seed, "base16");
const provider = new Ed25519Provider(key);
const staticDid = new DID({
resolver: KeyResolver.getResolver(),
provider
});
await staticDid.authenticate();
ceramic.did = staticDid;
return staticDid;
}
// we'll use this both for our query's filter and for signing/verifying data
const did = await authenticateDID(SECRET_KEY);
const exists = await composeClient.executeQuery<{
node: {
pointClaimsList: {
edges: {
node: {
id: string;
data: {
value: number;
refId: string;
timestamp: string;
context: string;
}[];
issuer: {
id: string;
};
holder: {
id: string;
};
issuer_verification: string;
};
}[];
};
} | null;
}>(`
query CheckPointClaims {
node(id: "${`did:pkh:eip155:${chainId}:${address.toLowerCase()}`}") {
... on CeramicAccount {
pointClaimsList(filters: { where: { issuer: { equalTo: "${did.id}" } } }, first: 1) {
edges {
node {
id
data {
value
refId
timestamp
context
}
issuer {
id
}
holder {
id
}
issuer_verification
}
}
}
}
}
}
`);- Use the data passed into the API's request body to sign and encode the values with our application's DID (if no
PointClaimsinstance exists) - Decode and verify the existing values of "issuer_verification" against our application's DID before appending the new data, resigning, and re-encoding it with our application's DID (if a
PointClaimsinstance does exist)
if (!exists?.data?.node?.pointClaimsList?.edges.length) {
const dataToAppend = [{
value: parseInt(value),
timestamp: new Date().toISOString(),
context: context,
refId: refId ?? undefined,
}];
if (!refId) {
delete dataToAppend[0]?.refId;
}
const jws = await did.createJWS(dataToAppend);
const jwsJsonStr = JSON.stringify(jws);
const jwsJsonB64 = Buffer.from(jwsJsonStr).toString("base64");
const completePoint = {
dataToAppend,
issuer_verification: jwsJsonB64,
streamId: "",
};
return res.json({
completePoint
});
}
else {
const dataToVerify = exists?.data?.node?.pointClaimsList?.edges[0]?.node?.issuer_verification;
const json = Buffer.from(dataToVerify!, "base64").toString();
const parsed = JSON.parse(json) as DagJWS;
const newDid = new DID({ resolver: KeyResolver.getResolver() });
const result = parsed.payload
? await newDid.verifyJWS(parsed)
: undefined;
const didFromJwt = result?.payload
? result?.didResolutionResult.didDocument?.id
: undefined;
if (didFromJwt === did.id) {
const existingData = result?.payload;
const dataToAppend = [{
value: parseInt(value),
timestamp: new Date().toISOString(),
context: context,
refId: refId ?? undefined,
}];
if (!refId) {
delete dataToAppend[0]?.refId;
}
existingData?.forEach((data: {
value: number;
timestamp: string;
context: string;
refId: string;
}) => {
dataToAppend.push({
value: data.value,
timestamp: data.timestamp,
context: data.context,
refId: data.refId,
});
});
const jws = await did.createJWS(dataToAppend);
const jwsJsonStr = JSON.stringify(jws);
const jwsJsonB64 = Buffer.from(jwsJsonStr).toString("base64");
const completePoint = {
dataToAppend,
issuer_verification: jwsJsonB64,
streamId: exists?.data?.node?.pointClaimsList?.edges[0]?.node?.id,
};
return res.json({
completePoint
});
} else {
return res.json({
err: "Invalid issuer",
});
}
}- Send the result back client-side
- Use our client-side ComposeDB context (on which our end user is already authenticated) to either create or update a
PointClaimsinstance, using the results of our API call as inputs to our mutation
//if the instance doesn't exist yet
if (finalPoint.completePoint.dataToAppend.length === 1) {
data = await compose.executeQuery(`
mutation {
createPointClaims(input: {
content: {
issuer: "${did}"
data: ${JSON.stringify(finalPoint.completePoint.dataToAppend).replace(/"([^"]+)":/g, '$1:')}
issuer_verification: "${finalPoint.completePoint.issuer_verification}"
}
})
{
document {
id
holder {
id
}
issuer {
id
}
issuer_verification
data {
value
refId
timestamp
context
}
}
}
}
`);
}Does this sound a bit tedious? This is the same pattern we're using for issuing and verifying badges as well. And yes, it is verbose compared to what our code would've looked like had we decided not to go through the trouble of allowing our participants to control their Ceramic data.
Creating Manifestations
As mentioned above, PointMaterializations represent how points manifest in a platform for reward structures (like a new badge, an aggregation for a leaderboard, or gating an airdrop). Most importantly, the PointMaterializations collection is a new dataset built from our composable piece PointClaims.
To create PointMaterializations, we use an event-driven architecture, leveraging our MVP EventStream feature. When PointClaims instances are written to Ceramic, we will receive a notification in another application, in this case, a Fluence compute function.
Our compute function works like this
- Determine that the notification is for the model (
PointClaims) and the issuer is the DID of our application. - Extract from the notification content the
PointClaims - Verify that the
issuer_verificationis valid for thedatafield inPointClaims - If the subject of the
PointClaims(the document owner) has an existing PointMaterializations, retrieve it, otherwise create a new one. - For the context of the
PointMaterializationscalculate a new valueunique-events: tally all thecontextunique entries in thedatafieldall-events: tally all the entries in thedatafieldfirst-all-events: similar to all events, we check all uniquecontextentries in thedatafield. If they have attended all the events, we then record the latest first event check-in as the value, so that we can rank users by that time
If you want to view the Rust code that implements the sequence above, please check out the compute repository.
At the time of writing, the EventStream MVP does not include checkpointing or reusability, so we have set up a checkpointing server to save our state and then use a Fluence cron job, or spell, to periodically run our compute function. In the future, we hope to trigger Fluence compute functions from new events on the EventStream.
What We Learned
This exercise left our team with a multitude of valuable learnings, some of which were more surprising than others:
Wallet Safety and Aversion to Wallet Authentication
We optimized much of the flow and the UI for mobile devices, given that the expected flow required scanning a code/tapping a disc as the entry point to interact with the application. However, throughout EthDenver and the various events we tried to facilitate issuing points, we overwhelmingly noticed a combination of:
- Participants intentionally do not have a MetaMask/wallet app installed on their phones (for safety reasons)
- If a participant has such a wallet app on their phone, they are VERY averse to connecting it to our scavenger hunt application (particularly if they haven't heard of Ceramic previously)
This presents several problems. First, given that our flow required a scanning/tapping action from the user, this almost entirely rules out using anything other than a phone or tablet. In a busy conference setting, it's unreasonable to expect the user to pull out their laptop, hence why those devices were not prioritized in our design.
Second, the end user must connect their wallet to sign an authentication message from Ceramic to write data to the network (thus aligning with our user-centric data design). There's no other way around this.
Finally, our scavenger hunt application stood ironically in contrast with the dozens of POAP NFC stands scattered throughout the conference (which did not require end users to connect their wallets, and instead allowed them to input their ENS or ETH addresses to receive POAPs). We could've quite easily architected our application to do the same, though we'd sacrifice our user-centric data design.
SET Account Relation will be Useful in Future Iterations
As explained above, the PointsClaims model presents an ideal opportunity to use the SET accountRelation configuration in ComposeDB (given how we update an existing model if it exists).
Data Verifiability in User-Centric Data Design Entails More Work
Not a huge shocker here, and this point is certainly relevant for other teams building with Verifiable Credentials or EAS Off-Chain Attestations on Ceramic. While there are plenty of considerations to go around, we figured that our simple use of an encoded JWT was sufficient enough for our need to validate both the originating DID and the payload. It was hard to imagine how we would benefit from the additional baggage relevant to saving point-related VCs to ComposeDB.
Interested in Building Points on Ceramic?
If your team is looking for jam on some points, or you have ideas for how we can improve this implementation, feel free to contact me directly at mzk@3box.io, or start a conversation on the Ceramic Forum. We look forward to hearing from you!