
Data Control Patterns in Decentralized Storage
Breaking down predominant data control patterns on Ceramic


The Data Provenance article outlined several differentiating features while comparing Ceramic to smart contract platforms and centralized databases. When observed through the lens of the provenance and lineage of data, many challenges and design choices are inherently unique to a peer-to-peer, multi-directional replication layer that enables multi-master, eventually consistent databases to be built on top. As the article referenced above points out, the paradigm of true “user-controlled data” does not exist in traditional database terms, since user-generated content is authored by dedicated servers on the users’ behalf.
More recently, our team has been discussing and working on additional features to ComposeDB that feel different compared to those aimed to provide functional parity with what developers should expect from a database layer. Whereas the ability to filter and order based on schema subfields feels like a basic utility expectation, our more recent discussions around introducing features that allow developers to define single-write schemas, for example, call on use cases unique to decentralized data.
These feature ideas, and more importantly the problem statements behind them, impact certain patterns of data control more than others. These different architectural patterns are what we’ll attempt to unpack below by tying together their design, specific needs, how teams are currently building with them, and what role they play in the broader dataverse.
Users vs. Apps: Data Creation and Ownership
We’ve broken down these predominant patterns in the table below:
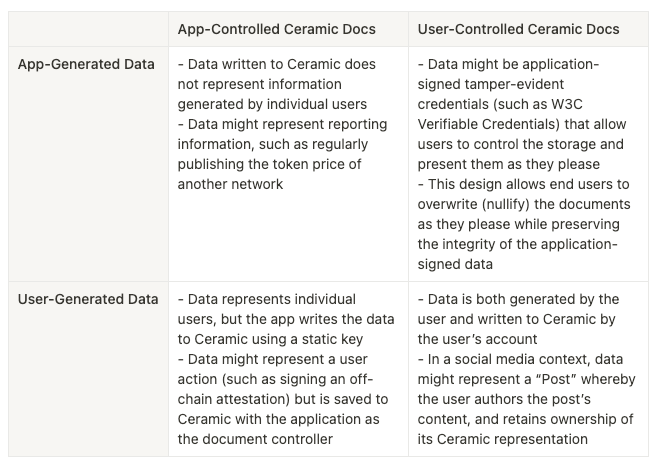
Before we dive in, it’s important to point out that the way Ceramic “accounts” (represented by DIDs) interact with the network is itself a novel paradigm in data storage, and more akin to blockchain accounts transacting with a smart contract network. This is an important key to the underlying architecture that allows for the diversity of “data control” outlined in the table above. This article assumes readers are already familiar with this setup, at least on a basic level.
Finally, our position on these patterns is of the perspective that all are necessary and important to a diverse data ecosystem. As we’ll outline below, these emergent behaviors arise from the real needs of the applications that use them and their users. We hope that this article will help developers understand why these different models exist, what trade-offs and considerations they incur, and use that information to approach their data design in a more informed way.
With that out of the way, let’s dive deeper into each of these patterns.
Application-Generated, Application-Controlled
When I think of an archetypal use case for this quadrant, the idea of a “data oracle” comes to mind. That oracle is responsible for:
- Bridging the “gap” between two disparate networks by reporting data
- Reliably providing said data in an opinionated, predictable, and steadily frequent way
Looking at it through this lens, the “application-generated” thought transforms into more of an “application-provided” idea. Though the data itself originates elsewhere, the role of the oracle is to retrieve it, transform it into whichever format is needed by the storage layer, and write it to its final destination.
There are commonalities in behavior across teams creating and using this data quadrant:
Use of DID:Key
- Unsurprisingly, an application dedicated to writing reporting data to Ceramic frequently will be using a static seed (or set of static seeds) to authenticate DID:Key(s) on the Ceramic node
Server-Side Generation, Server-Side Writes
- Given that the method used to write data to Ceramic doesn’t require authentication with a browser wallet, this action can be easily created as a server-side service
- Similarly, another server service would be responsible for retrieving data from the data source and transforming it before supplying it to the service that writes it to Ceramic
Application as the Trusted Vector
- Other teams relying on data provided by an oracle need to trust that the service won’t have intermittent failures
Data Availability Motives
- As far as composability goes, the application writing the data, along with other applications building on that data, are incentivized to sync the data to ensure persistence
Unique Needs
- Beyond basic sorting and filtering needed by any applications building on this data type, not much is needed
- Consumers of this data (which is likely the application that controls it) trust the logic that was used to write the data to the network
Ceramic Example
- Orbis authors Pricefeed Data to Ceramic to serve as an oracle
Application-Generated, User-Controlled
As outlined in the table, a great example that falls into this category would be credential data. In the analog world, universities issue diplomas to their students. The diploma is typically signed by the university’s chancellor or president, but the physical document is transferred and kept by the student (I understand that this is not a perfect analogy in the sense that it’s typically the university that verifies a student has received a diploma by employers or other interested parties).
In a broadly similar sense, this category manifests in Ceramic as tamper-evident data that are cryptographically signed by the application but point to the end user that controls its storage. Perhaps the data is encrypted by the user before it’s stored in Ceramic, with access control conditions to grant only whitelisted parties viewing abilities. Due to its tamper-evident qualities, all parties can rest assured of the fidelity of the data’s contents.
Here are some commonalities:
Use of DID:PKH
- The resulting Ceramic documents are almost always written by the user with an authenticated session created by their blockchain wallet
Server-Side Generation, Client-Side Writes
- In the case of credentials, the application is likely using a static key to generate payloads server-side (once certain application conditions are met) and passes the payload to the user to write with the authenticated session stored in the browser
Application as the Trusted Vector
- What matters most for consumers of this data is the application that attested to it and signed it
- While the user has technical control over the data and who they share it with (if they encrypt it), they cannot change the data’s values
Data Availability Motives
- We can assume that some of this data will be highly valuable—perhaps the application that issues the credential is highly respected and unlocks a lot of gates for the end user
- The user that controls these documents will likely be the most compelled party to keep this data available. It will be important for other applications that consume this data, but arguably not as much
Tamper-Evident, Cryptographically Signed
- Behavior is already aggregating along the lines of standards and formats like Verifiable Credentials and EAS Off-Chain Attestations
Unique Needs
- Under the use case example referenced above, applications that issue data for their users to store typically don’t reference other data (for example, a relation to another Ceramic document) that can easily be changed—each data object is inherently
whole - Therefore, I’d argue no unique needs are obvious or necessary for this quadrant either
Ceramic Example
- Gitcoin Passport issues Verifiable Credentials to its users while giving the users Ceramic ownership of their instances
User-Generated, Application-Controlled
This unique category feels most similar to what we’re used to in Web2, though the use cases in Ceramic might be somewhat novel. For example, if you think back to the tamper-evident qualities of an application-generated credential that’s stored by the user we referenced in the last section, the inverse could be necessary for some applications. Perhaps an application wants to create a petition that’s cryptographically signed by multiple users, but ownership of the final document that aggregates the individual signatures should be in the hands of the facilitator.
Perhaps the broader use case is positioned around collaboration, allowing individuals to input into the document with the resulting document representing that unified effort.
In terms of commonalities:
Use of DID:Key
- The application will most likely be authoring Ceramic documents using a static seed or set of seeds
Client-Side Input, Server-Side Transformation, Server-Side Writes
- Under this design, it’s likely that the application is receiving input from user browser sessions but is set up such that once a condition has been met, it will transform the data into the format necessary to write it to Ceramic
Application Server May or May Not Require Trust
- If the inputs from the users are in a format that’s tamper-evident, end users interacting with this setup simply need to trust that the server writes the data to Ceramic, but do not need to worry about data fidelity
Data Availability Motives
- If the application’s primary value proposal is its ability to facilitate coordination across users or transform data in creative ways, the controlling application is most motivated to keep the data available (alongside other applications consuming it)
Unique Needs
- Feature needs for this quadrant should be highly similar to the “application-generated, application-controlled” category, in the sense that the application can trust the static logic of its servers not to intentionally change and ruin its data
User-Generated, User-Controlled
We anticipate this final category to eventually be the most common across applications built on Ceramic, and much of the momentum we’ve witnessed thus far aligns with that narrative. More importantly, while each of these categories is valuable to the ecosystem, this one speaks most to the narrative around data interoperability, making the concept of users interacting with the same data primitives they own across disparate environments and applications possible.
A great showcase example would be a social application framework that allows users to create posts, comment on posts, and react to content, all tied together by a parent “context” representing an application environment. Other social applications can read from and build off of the same content artifacts, or define a unique context that uses the same data primitives but swaps out the connective tissue.
Under this model, users have sovereign control of their documents. Even if a user creates a session key that allows a malicious application to write incorrect data on their behalf, the session key will ultimately expire (or is manually revoked by the user), the application loses its write privileges, the Ceramic document never transfers ownership, and the user overwrites the data. End users are equally free to spin up custom UIs and nodes and edit their data that will render in the interfaces of the applications that defined those models.
However, high flexibility brings important considerations:
Use of DID:PKH
- This shouldn’t be surprising since most users will be creating authenticated sessions from their browser wallet
Client-Side Generation, Client-Side Writes
- This also shouldn’t be controversial given that the inputs are coming from end users, and their sessions are authenticated to write the data to Ceramic
Network Data Sync
- This is where more complexity comes into play. For the data users generate to propagate and become usable between applications, their underlying Ceramic nodes must sync and share information
- While a multi-node architecture may be required for a single application (in which case the data sync is still important as far as performance goes), in this context I’m referring to data sharing across nodes operated by separate applications
- To reduce or eliminate the necessity of trust between application environments, the underlying protocol must have built-in features to ensure data fidelity. Team A should not have to rely on the competency of Team B, and shouldn’t suffer if Team B somehow messes up
Data Availability Motives
- Interest in keeping the data available should be fairly shared between the end users and the applications that use it
Ceramic Example
- Orbis is a social data model that provides intuitive tooling for developers who want to build social timelines, comment systems, private messaging, and more
Unique Needs
- I think this is where we wade into territory that’s best illustrated by hypothetical situations:
Let’s say a trust system for open-source software plugins is built on Ceramic. Individual plugins are represented by ComposeDB models. For example:
type Plugin
@createModel(accountRelation: LIST, description: "A simple plugin")
@createIndex(fields: [{ path: "name" }])
@createIndex(fields: [{ path: "created" }])
@createIndex(fields: [{ path: "checkSum" }])
{
owner: DID! @documentAccount
name: String! @string(maxLength: 100)
description: String @string(maxLength: 100)
created: DateTime!
checkSum: String! @string (minLength: 64, maxLength: 64)
}Let’s assume that the checkSum field in this example represents the SHA-256 hash of the plugin’s code.
For people to trust and use the plugins, they rely on representations of user-generated trust:
type Plugin @loadModel(id: "...") {
id: ID!
}
type Trust
@createModel(accountRelation: LIST, description: "A trust model")
@createIndex(fields: [{ path: "trusted" }])
{
attester: DID! @documentAccount
trusted: Boolean!
reason: String @string(maxLength: 1000)
pluginId: StreamID! @documentReference(model: "Plugin")
plugin: Plugin! @relationDocument(property: "pluginId")
}Under this current setup, you can easily imagine the following problematic situations:
Plugin Areceives a ton of authentic, well-intentioned trust signals over a few weeks. The controller of thePlugin Astream then decides to switch out the value of thecheckSumfield to refer to a malicious plugin that steals your money. Because the relationship is defined by the plugin’s stream ID, those positive trust signals will by default point to the latest commit in the event log (the malicious plugin)Plugin Areceives a ton of deceptive positive trust signals, all fromAccount A. Because (at the time of writing this article) there’s nothing that preventsAccount Afrom doing so,User Interface AandUser Interface Bare left to do some custom client-side work to sort through the noise and present the truth to the end user. Since there are multiple ways of doing so, mistakes are made byUser Interface B, and the end user is tricked yet again
You can start to see the real ways these issues simply don’t exist elsewhere under the safeguard of an application’s server preventing adverse or unexpected behavior.
Solutions Actively Underway
Bringing this back to Ceramic’s current roadmap, we have two active feature integrations we’re working on to address these unique problems, each of which is actively in request-for-comment stages:
Native Support for Single-Write Documents (field locking)
This active RFC (request for comment) details a feature that would allow developers to define schemas that prevent certain fields within a model from being updated after the document is created. Using the Plugin example above, you can imagine how this might be useful in preventing a Plugin controller from maliciously updating key fields like checkSum to prevent users from being tricked.
A refactor of the Plugin schema definition using this feature might instead look like:
type Plugin
@createModel(accountRelation: LIST, description: "A simple plugin")
@createIndex(fields: [{ path: "name" }])
@createIndex(fields: [{ path: "created" }])
@createIndex(fields: [{ path: "checkSum" }])
{
owner: DID! @documentAccount
name: String! @locking @string(maxLength: 100)
description: String @string(maxLength: 100)
created: DateTime! @locking
checkSum: String! @locking @string (minLength: 64, maxLength: 64)
}While actual syntax may vary, the @locking directive here is meant to identify the subfields that would be prevented from being updated after the document is created (most importantly, the checkSum).
Native Support for Unique-List Documents (”SET” accountRelation)
This RFC would help prevent situation #2 above from happening. While ComposeDB would currently allow Account A from creating as many Trust instances for Plugin A as they wanted (thus leaving it up to the competency and inference of the applications or interfaces using that data to resolve), this instead would make the following possible:
type Plugin @loadModel(id: "...") {
id: ID!
}
type Trust
@createModel(accountRelation: SET, accountRelationField: "pluginId")
@createIndex(fields: [{ path: "trusted" }])
{
attester: DID! @documentAccount
trusted: Boolean!
reason: String @string(maxLength: 1000)
pluginId: StreamID! @documentReference(model: "Plugin")
plugin: Plugin! @relationDocument(property: "pluginId")
}Under this design, users can create as many instances of Trust as they want, but prevents them from creating more than 1 for any 1 plugin, given that the constraining field is on the pluginId field.
Get Involved
For you readers who find this problem space compelling, or want to get involved in ways that help shape the future of ComposeDB, we encourage you to react in the forum to the RFCs we mentioned above. Here are those links again:
Native Support for Single-Write Documents (field locking)
Native Support for Unique-List Documents (”SET” accountRelation)
Do you see additional gaps between our current functionality and the needs of the four design quadrants we outlined above? Let us know! Create an RFC of your own on the forum using the same format in the two above.