
Optimizing Ceramic: How Pairwise Synchronization Enhances Decentralized Data Management


In the past months we have replaced the algorithm at the heart of the ceramic database. This post explains why we made the change from Multicast to pairwise synchronization but first let review the design motivations of Ceramic.
“Information also wants to be expensive. Information Wants To Be Free. ...That tension will not go away.” Stewart Brand. There is tension since data storage is a competitive market but data retrieval can only be done by the service that has your data. At 3Box Labs, we want to catalyze a data ecosystem by making community driven data distribution not only possible but available out of the box. Ceramic is a decentralized storage solution for apps that are dealing with multi-party data and that is more scalable, faster and cheaper than the blockchain.
Data vendor lock-in
Many organizations and individuals have data that they want to publish and Ceramic lets them do so without instant data vendor lock in for storing their own data. In the Web2 era, data often becomes ensnared within exclusive services, restricting its accessibility and durability. Access to this data requires obtaining permission from the service provider. Numerous platforms have vanished over the years, resulting in significant data loss like GeoCities, Friendster and Orkut. Even within still existing companies like Google, numerous lost data products are documented. See killed by google.
We can break free from this risk by creating data-centric applications that multihome the data. Ceramic is the way to have many distinct data controllers publishing into shared tables in a trustless environment. Each reader can know who published what content and when they did without relying on trusting the storage service to keep accurate audit logs. Since each event is a JSON Document, signed by a controller, timestamped by ethereum, and in a documented schema it can be preserved by any interested party, with or without permission from the storage vendor.
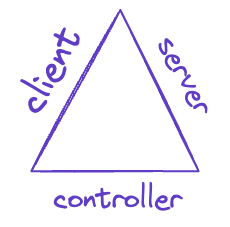
In Ceramic we separate the roles of data controllers from the data servers. By allowing data to live on any preferred server the data is durable as long as any server is interested in preserving the data. This allows data to outlive a particular data server, paired with the durability of data living in multiple places and the speed/reliability of operating on local data.
Document the schema
Throughout the history of the internet, we have witnessed numerous data services going away and taking the users data with them. While multihoming helps preserve data, it's useless without the ability to interpret it.
Ceramic preserves the data formats in two ways. The first is that the data lives in JSON Documents. This format allows us to reverse engineer and examine the data. The second is that the model schema gets published. The model schema contains both json-schema and human language description that the original developer can use to give machine and human context to the data. This enables both the preservation of the data and schema so the data can be understood and new apps can be made to interact with the preserved data.
{
"data":{
"accountRelation":{
"type":"list"
},
"description":"A blessing",
"name":"Blessing",
"relations":{
},
"schema":{
"$defs":{
"GraphQLDID":{
"maxLength":100,
"pattern":"^did:[a-zA-Z0-9.!#$%&'*+\\/=
?^_`{|}~-]+:[a-zA-Z0-9.!#$%&'*+\\/=?^_`{|}~-]*:?[a-zA-Z0-9.!#$%&'*+\\/=?^_`{|}~-
]*:?[a-zA-Z0-9.!#$%&'*+\\/=?^_`{|}~-]*$",
"title":"GraphQLDID",
"type":"string"
}
},
"$schema":"https://json-schema.org/draft/2020-12/schema",
"additionalProperties":false,
"properties":{
"text":{
"maxLength":240,
"type":"string"
},
"to":{
"$ref":"#/$defs/GraphQLDID"
}
},
"required":[
"to"
],
"type":"object"
},
"version":"1.0",
"views":{
"author":{
"type":"documentAccount"
}
}
},
"Header":{
"controllers":[
"did:key:z6MkgSV3tAuw7gUWqKCUY7ae6uWNxqYgdwPhUJbJhF9EFXm9"
],
"model":{
"/":{
"bytes":"zgEEAXFxCwAJaG1vZGVsLXYx"
}
},
"sep":"model"
}
}Example schema document
Information retrieval
The key to multihome data is being able to retrieve the data from a server that has it.
How do we move the data from the servers that have the data to the servers that are interested in storing it? When we first made Ceramic we used two multicast methods: The first was to do a gratuitous announcement of new data. Send the data to EVERY node in the network so that they can store it if they are interested in it. Second, if a node did not know about a stream then when requested by a user it would multicast a request to the whole network and take the latest version to come back as a response.
This worked but had several drawbacks. The first is that requests for streams that a node did not know used WAN traffic and would have unpredictable latencies. This meant that all applications needed to design for slow unpredictable retrieval times. The second drawback was that a node had no way to retrieve a complete set of the streams that matched their interests. They could only listen to the multicast channel and fetch any stream they happened to hear about. Any stream that they missed either because it happened before the node was online or during down time could be missed forever. Third, there is a performance cost to sending requests to nodes that have no mutual interest with your node. A node that did 100 events a year could not scale down since it would need to keep up with filtering announcements from nodes doing 100 events a second. If we wanted to support both very large and very small data centric applications we needed a new strategy. We even saw cases where a slow node could not keep up on the multicast channel harming the performance of larger more powerful nodes.
To solve these problems of performance, completeness, and scalability we switched to a pairwise synchronization model. Each node advertises the ranges of streams that the node is interested in. Each node only synchronizes the streams that are of mutual interest and the nodes synchronize pair wise.
Scalability
Since the nodes synchronize pairwise, no slow node can harm the ability of two healthy nodes to complete a synchronization. If two nodes have no intersection in their interests then the conversation is done. A range of streams that has 100s of events per second that your node is not interested in will not create work for your node. A node only needs to scale to the speed of events in the ranges it is interested in and the scale of any model you are not interested in costs you nothing. This solved our scale up / scale down objective.
Completeness
If the two nodes do have an intersection of their interests they will continue the synchronization until both nodes have ALL the events that the other node had when the synchronization began. There is no longer a need for high availability to be online either when the stream’s event was originally published or when some node queried for that stream. If the event is stored by either of the nodes both nodes will have it at the end of the pairwise synchronization. Once a node has pairwise synchronized with each of the nodes that are advertising an interest range that node has all of the events in that range as of the time of the synchronization. This solves the completeness objective.
More interestingly, the local completeness means that we can build local indexes over the events and do more complex queries over the events in the ranges nodes are interested in entirely locally.
Performance
Lastly, since we have a complete set of events for our interests we can serve queries about the events from the local node with no need for WAN traffic. This solves the performance objective for predictable fetch latencies.
Pairwise Synchronization in Logarithmic rounds
In the multicast model ceramic sends messages to all other ceramic nodes. One of the most notable differences with synchronization is that nodes do pairwise synchronization one peer at a time. The two peers will each send the other their interests. Both nodes filter the events that they have to find the set of events of mutual interest between the two nodes. Once this intersection is found we synchronize the set with a Range-Based Set Reconciliation protocol we call Recon.
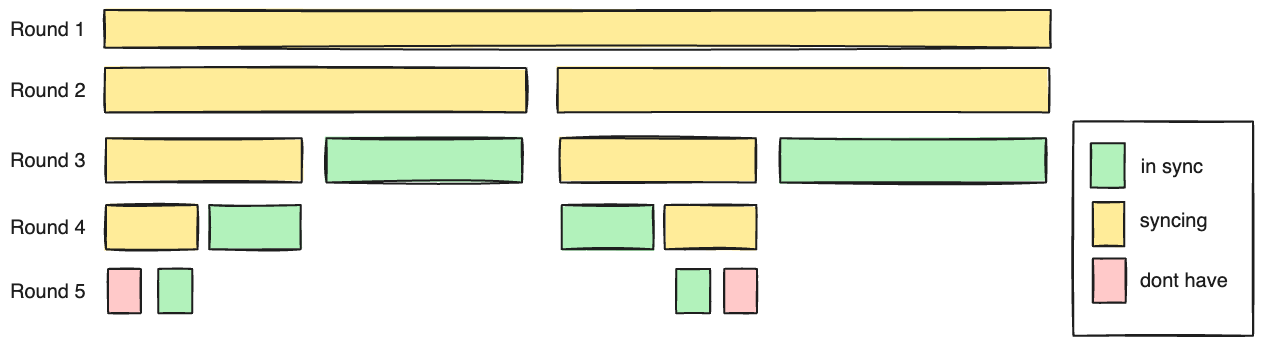
We can report progress in a Recon synchronization by reporting the percentage of events in the in sync vs syncing ranges. Alternatively we could render a bar like in the diagram showing which ranges are in which states.
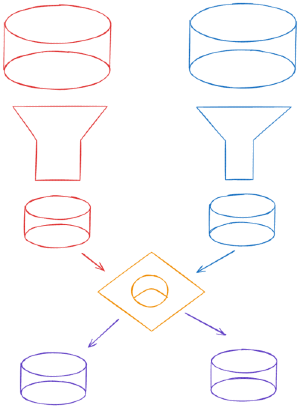
This is a divide and conquer protocol. We start with the full intersection as a single range. We pull a range off the work list and send the (hash, count) of all events in the range to the other side. They compare their own (hash, count) and respond accordingly.
The range splits are handled differently on the Initiator then the Responder. The Initiator maintains the work list and pushes all of the subranges onto the work list. The Responder just sends a message back with multiple ranges and hashes for each range. This keeps the synchronization state on the Initiator and reduces the burden on the Responder to a stateless call and response. This fits Recon into the http client server request response paradigm.
Exponential distribution
Now that we have replaced a multicast message to all nodes in the network with pairwise sync it is reasonable to ask if we have broken the exponential distribution we got from multicast trees.
How fast can data spread through the network? Now that we have replaced the multicast channel with pairwise connections, how do we match the exponential distribution of the multicast channel?
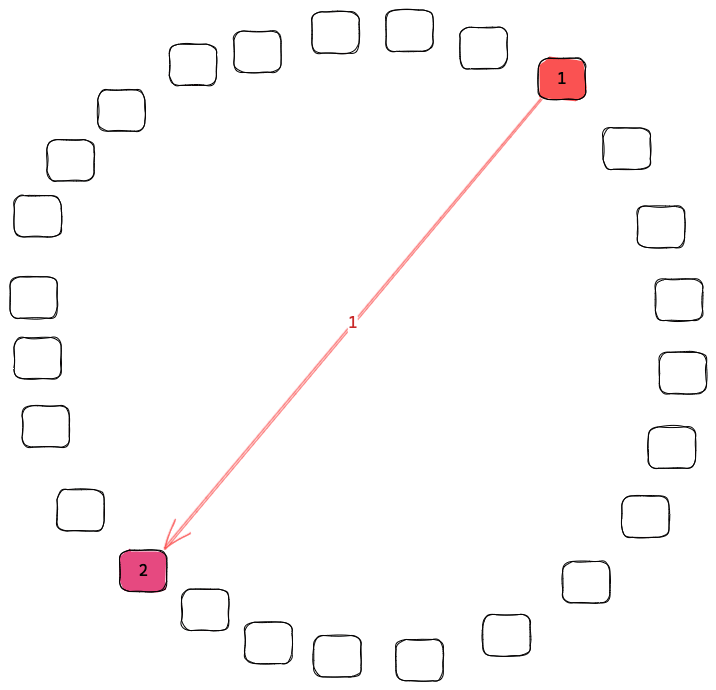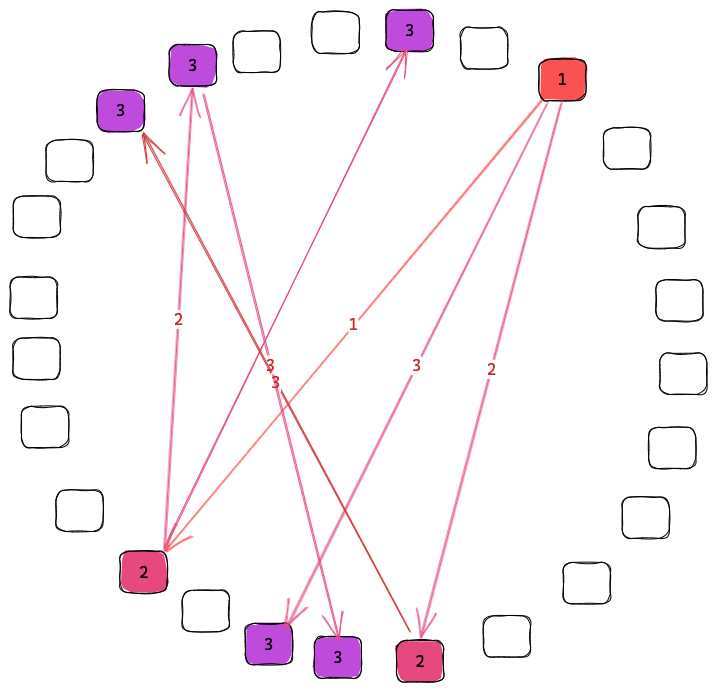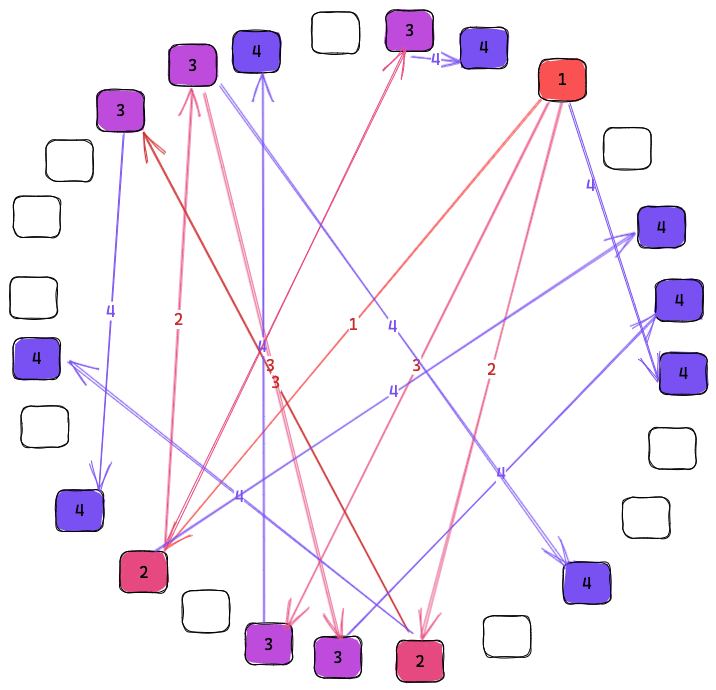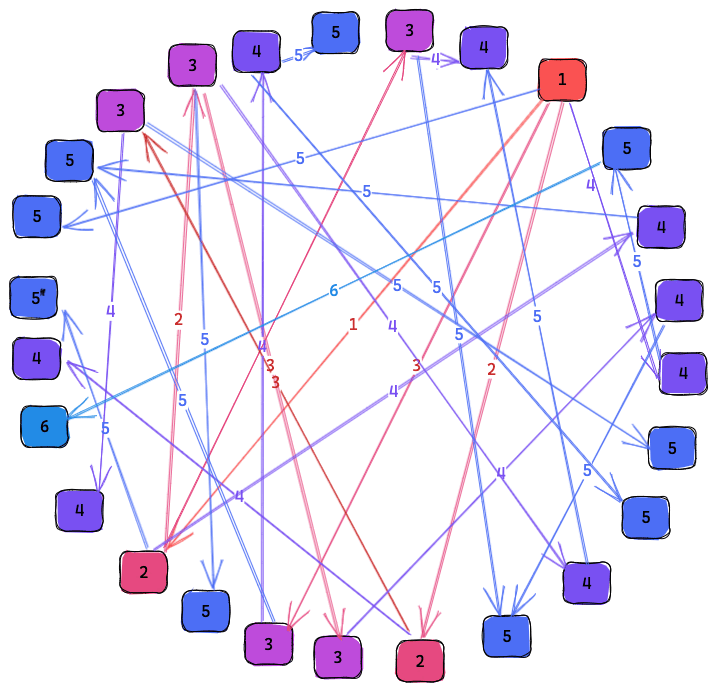
We get this property since each node cycles through connecting to all other nodes that advertise overlapping interests. When the node that originally received the event from a client there is 1 copy on the network. After the first sync there are 2. Then both of the nodes sync to new nodes giving 4. This will grow exponentially until almost all interested nodes have the data. At that point the odds that any node with the event calls a node without it is small but the odds that the node without the event calls a node with it is large. By using synchronization we get the benefits of both push and pull gossip protocols. Push which is fast when the knowledge of the event is rare and pull which is fast when knowledge of the event is common.
Summary
By using Set reconciliation to perform pairwise synchronization of node’s overlapping interests we are able to have performance, completeness, and scalability. The predictable performance of querying local data on your node. The completeness of synchronizing all of the events of interest preemptively. The scalability of not synchronizing the events that lay outside of the interests of a node. Pairwise synchronization protects the network from slow nodes from slowing down the rest of the network. It is now possible to scale up or down without performance and completeness problems. This enables developers to build data intensive applications without the data vendor lock-in from either the storage providing service or the application that originally read the schema.