
Demistifying Digital Identity


Identity has been a long-standing challenge not just in decentralized technology but in online applications generally. Part of the challenge comes from a lack of clarity about what is meant by ‘identity’ and the many forms it can take in digital products, services and networks. This is a frequent source of confusion and frustration to builders, leading many to avoid tackling identity altogether or implementing short-term workarounds. Each can have massive consequences, as identity’s importance and complexity grow with both product usage and maturity.
This two-part series helps break down identity for your digital application, service or product, especially for decentralized architectures and an interoperable web. The aim is to make a nebulous topic concrete, a big problem approachable, and a difficult and frothy space easy to analyze.
Part 1 breaks down the role of identity in digital products. This includes:
-A clear definition and scope for digital identity
-The value it should bring to your product or service
-What to know about common identity workarounds (including key pairs, on-chain IDs, 0auth logins, and custom solutions)
Part 2 shares what to demand from your identity infra. This includes:
-The key standards that it should be built upon
-5 characteristics and capabilities it must support
-A flexible model that fits your stack
- Steps to future-proof your architecture in less than 1 day
Digital identity is a fast evolving space with a deep history of academic and practical contributions (some of which I’ve tried to reference), and so is not always approachable. My view is informed by helping build uPort and 3Box, participating in community standards, and co-authoring a book on the sociology of identity. This series is by no means a complete history or a full view of identity, but I hope it is helpful in making a critical piece of infrastructure easier to understand and build upon.
What is Identity?
In the fields of sociology, psychology, and biology there is no accepted definition of identity. Academics in each range from strict category sets to fuzzy conceptions. Said famed psychologist Erik Erikson:
The more one writes about [identity], the more the word becomes a term for something that is as unfathomable as it is all-pervasive.
Erikson would later coin the term “identity crisis.”
The nebulous nature of the definition of identity carries into the digital world. When technologists speak about identity, they may be referring to a wide range of challenges, or a spontaneous subset of challenges that matter to their use case.

The facets of identity outlined in this diagram are not the same and the solutions to each vary greatly, however they are highly related. Understanding how these elements tie together under a common framework is critical to achieving success and can turn identity from a series of isolated pain points into one of the biggest simplifications and value-adds in your product architecture.
Whatever your goals and technical needs for identity, understanding should start at the human level — which is also where we often first go astray. For all of their imperfect definitions and disagreements, scholars nearly universally agree that, contrary to our instincts and vocabulary, identity is not static, singular, or individual. Identity is dynamic, plural, and social.
If we wish to build a truly connected, trusted, and usable Web3 that can scale to global usage, we should build on infrastructure that reflects this starting point. As we’ll see, a strong identity is not rigid, constant, and siloed but rather flexible, dynamic, and interoperable.
The role of identity in your product
If you are building an app (or wallet, service, platform, network), you probably want users. Those users may be mainstream consumers, developers, organizations, and/or DAOs. Whatever user type you are serving, the goal is the same: to have others interact with your product and realize value from it. This means you want to:
- Eliminate friction in signups, authentication, and engagement
- Deliver the richest possible experience, with little extra work
- Focus on your core value-add, without building new or redundant infrastructure in-house
- Build with a simple, elegant user model that can grow with your needs over time
The solution to each of these goals hinges on how you manage users. How do they authenticate (login)? Can they engage with each other (chat/comment)? Can you deliver persistent and personalized experiences across time, devices, logins? Can you easily integrate with the many other products and platforms that users are on?
In traditional web applications this is often broken into Identification (related to account creation, KYC, etc.), Authentication (login, anti-fraud), and Authorization (permissions, sharing). This sequential approach will change with more flexible decentralized models. Identity touches everything that has to do with how you manage, secure, serve and interact with your userbase.
Identity needs evolve with growth
The demands of managing a user base change quickly as your product grows.
Your biggest “identity” pain point today may be populating your app with basic public profile information so users can recognize each other. Next month it may be storing data for user history and application state, such past or in-process transactions (like a shopping cart). Next quarter it could be basic KYC, and next year it could be anti-sybil protection. Each of these product requirements addresses a different “identity” problem with differing potential solutions.
- Profiles: Should I implement 0auth or an IPFS hash mapped to a key? But what if the user rotates keys or uses more than one key?
- Data storage: Should I store data in a Textile ThreadsDB? But how do I allow users to manage access control without adding more key types and friction?
- KYC/Proof of human: Should I use a service like Passbase or tech from Democracy Earth? How do I map this proof to existing users?
- Anti-Sybil: Should I use a service like BrightID or Idena? Then how do I map their graphs to my user base?
Implementing any of these solutions independently clearly has its own challenges, but your biggest pain point will arise from not using the correct identity infrastructure from the beginning to tie them all together in a future-proof way. A strong and flexible identity infrastructure can make each of these new needs natural extensions of previous ones, rather than new siloed challenges that need to be tackled independently and then later frankensteined together.
Identity is the infrastructure that lets you effectively tie together any capabilities that relate to your users
Good identity infrastructure should make meeting your evolving user-related needs easy and painless. If you’ve ever used Okta or Rippling, you understand that this is what they try to do for enterprises. They aim to provide a single system of record for users and accounts, however they do this in a defined, limited, and controllable enterprise environment. In a more open and undefined environment — like Web3 — a good identity infrastructure needs to work in a permissionless and limitless context, in a predictable way.
This means your identity infrastructure must be both customizable enough to suit your own needs but flexible enough to work well with many other existing solutions. It should be extensible and interoperable across many different networks, accounts/keys, and use cases. It should work not just with the other tools and services you are using, but the others your users are using and others that you may need in the future. Not only will this make identity management easier, but it will allow each solution to build upon the others creating compounding value. For example, the KYC verification could leverage existing user profile information, and the anti-sybil tool could leverage the existing KYC (and any other) verifications.
Perhaps most importantly, the identity system should operate without reliance on a single organization, platform, or model. The identity infrastructure should be an open and shared protocol, and the identities themselves should be user-managed and self-sovereign.
The problems of building without proper identity infrastructure
🔑 Single key pair identities
In the crypto world today, the default user “identity” tends to be a public blockchain account key. It’s logical why this might be the case: blockchain keys are already needed to manage assets so they’re widely possessed by users, and there are now many great wallets & SDKs for managing them. In reality, keys and the KMS solutions (wallets) to manage these keys are a fantastic way to authenticate into an application and execute on-chain transactions, however single key pairs cannot be the user identity infrastructure for any product that wishes to scale to meaningful and persistent usage.
Problems with using individual key pairs as identity:
- Compromises privacy: There is no chance of segregated or private activity, since all transactions by the same ‘identity’ must happen with the same public key.
- Creates fragility: When keys are used for signing and/or encrypting data, then all user data and history related to your product is lost when their key is lost or changed/rotated.
- Creates silos: Information can be accessed by that specific key only, with no chance of interoperability and composability across wallets and networks. This is counter to the vision of Web3.
- Adds complexity: Adding distributed databases and other user technology to your stack is difficult since they operate with different cryptographic identity and access control systems.
- Foregoes network effects: You have to bootstrap your own user network, profiles, and data from scratch rather than draw on existing data to easily onboard users and jump past a cold start.
Key pairs and wallets are a core part of the Web3 experience, but they should complement (and integrate tightly with) great identity infrastructure.
🔗 On-chain, network-specific identities
The limitations of relying on single key pairs for identities has been well understood in the blockchain ecosystem for years, leading to attempts at both smart contract based identities and network-specific identity standards. uPort pioneered approaches like Ethereum smart-contract based identity in 2016, social recovery in 2017, and EIP 1056 in 2018 (Joel Thorstensson, Pelle Braendgaard). Fabian Vogelsteller authored multiple versions of ERC-725, and many others have attempted to build multi-key identity models for Ethereum or other blockchain networks.
Problems with using on-chain, network-specific identifiers as identity:
- Compromised privacy: Using on-chain registries or smart contracts for storing identity information (such as ERC-725 or ERC-1056) is highly likely to compromise user privacy or control. PII should never go onto an immutable network or datastore.
- Network lock-in: Requiring creation of different identities for each network you or your users leverage leads to a terrible developer and user UX in a cross-chain world.
- Technology lock-in: More time, cost, and complexity to manage as new blockchains, technologies, and user patterns emerge.
- Limited interoperability: Inability to easily draw on data or identities from other networks.
While an improvement over using keys, identity standards built for a single network — and reliant on a single blockchain like Ethereum — lock us into new silos and a worse-than-web2 user experience. We are moving to a multi-chain future, with networks like Filecoin, Arweave, Flow, Near, Celo and Solana all coming online and adding value that complements what is being built on Ethereum. A better system needs to separate the identifier (or identity) from any specific network so it can be used with keys from across networks.
📩 0auth logins
Some applications may be fine to use centralized services for authentication in the short term. This can ease onboarding UX (especially before improved wallet SDKs). But this approach will not scale for apps that wish to deliver great and full Web3 experiences. Web2 logins are a viable authentication method, but not an identity solution.
Problems with using Oauth services as identity:
- Backend complexity: The need to build and maintain user tables to keep track of internal mappings between 0auth tokens, your internal user identity, your users’ blockchain account, and other user information like assets, transactions, and data.
- Fragmented user data: No association between the login method and other web3 experiences. This means that developers miss out on access to the open network effects and data history built around users’ keys as usage of other web3 products grows.
- Reliance on third-party auth: The authentication capability relies on a middleman service that sits between you and your users, adding both risk and complexity.
- Expensive and bulky: Web2 middleman services don’t scale for highly used, lightweight apps; cryptographic authentication is not just more secure, but far more efficient.
Web3 decentralized key management and authentication has come a long way since its early days and can now match 0auth in terms of user onboarding and UX. For great products in this space, check out: Magic, Torus, Metamask, Portis/Shapeshift, Argent, Rainbow, and WalletConnect.
⚒ Custom identity solutions
Recognizing the limitations of existing identity approaches, many applications or platforms have tried to create custom identity solutions that meet their needs. This is understandable and in some cases perceived to be more expedient. However most quickly find that there are reasons why identity has presented a difficult set of challenges not just in Web3, but since the dawn of the internet.
Problems with using custom identity solutions:
- High risk: Expensive and critical risks could easily arise by accidentally compromising user privacy, missing security vulnerabilities and fragility (e.g., key revocation), and meeting regulatory requirements (GDPR and right of users to delete data). Wading into this territory without a deep understanding of what has made identity challenging for decades is a big burden to take on. At best it adds massive complexity, and at worst it can permanently compromise the trust of your users and/or developers.
- Tech fragility: Custom solutions usually only function for a bespoke, specific, predefined use case. They don’t scale well to other new circumstances within your application, or use cases (and interoperability) beyond your app.
- Ecosystem exclusion: Custom solutions lock your users (and their identities) out of future identity-related advances developed by the broader community, such as better recovery options, new authentication providers, new databases, and services. To be easily usable, identity systems must “speak the same language’ in cryptography and schema, and custom solutions usually will not.
A few custom implementations may have been necessary in the interim while good decentralized identity solutions developed, but it’s critical to at least build on the core, lightweight standards that will ensure future-proof, lower risk, and more scalable identity capabilities over time.
Identity as a unifying advantage
Web3 is a collective movement being built globally, across many different blockchains, distributed databases, and ecosystems. Identity is the most essential piece for interoperability across these various technologies and communities. While smart contract and asset interoperability is convenient, user adoption of Web3 tech depends on a persistent, rich and manageable UX across applications.
A world in which end-users need to juggle many keys and wallets (and keep track of which to use in every scenario) is a world in which users simply do not adopt Web3. On the other hand, one of the biggest potential competitive advantages that the Web3 movement has over the Web2 status quo is shared permissionless networks, which allow developers to collectively build up and build upon existing network effects of users, data, and experiences faster than any siloed Web2 product.
Shared networks and network effects is the biggest GTM advantage that Web3 has over Web2. Shared identity is the key to leveraging that.
If Web3 identity systems silo users and their data resources by each individual blockchain or application, we are crippling ourselves since the movement becomes a collection of parts not the sum of them. Each of our products becomes locked into a smaller, less powerful, less attractive market and capability set.
Interoperable identity will let users move seamlessly across networks with all of their information, reputation, claims, data, and identity, and will let developers build not just with composable assets but with composable networks, users, and data, and services.
The key to making this a reality is a basic, shared, flexible identity standard that works on any stack, gives it new capabilities, and connects it to a growing ecosystem of others doing the same.
Part 2: A powerful and flexible identity standard
Good identity infrastructure should make it easy for you to manage all of the user-related capabilities in your product, service, or ecosystem. Common workarounds (outlined in Part 1) usually fail at this. Frequently they don’t preserve privacy. Usually they are too fragile to accommodate additions or changes. And even the best implementations don’t have the proper underpinnings to support the interoperability needed to easily extend to new capabilities and use cases over time. A good identity infrastructure should work simply today and adapt easily to future product needs and opportunities.
A common standard for digital identity can provide a simple and vetted solution for an extremely wide range of identity-related requirements, guarantee resilience and trust, and unlock powerful interoperability and opportunity. It can give any application the ability to manage users in the way they need, while ‘speaking the same language’ as other applications, services and networks that they may want to leverage or serve in the future.
This post shares a positive and concrete outline of:
1. The minimum requirement for interoperable identity: DIDs
2. The 5 capabilities needed for a powerful identity system
3. A flexible graph model for identity infrastructure
4. Practical implementations, including easy steps you can take now
The starting standard for identity
An identity system ties many related capabilities together. These anchor around identifiers for users and other entities that interact with your application or network. A standard model for these identifiers ensures that users, data, capabilities, and applications can work together even if they have different starting conditions or implementations. This decentralized standard is the necessary precondition to a flexible identity system.
DIDs: the minimum requirement for interoperability
The DID spec from the W3C is the widely-accepted standard for decentralized identifiers. It ensures identity systems can interoperate across many different networks and contexts. DIDs provide a common format for a globally-unique identifier that is an abstraction from any single key pair.
// Example of a 3ID DID method
did:3:bafyreib5c5gwpwzxl4pcrl7qw4j6lvgg7ug4zdflnhg2eqvuiw7kv7fng4Therefore unlike key pairs, DIDs can:
- Support multiple keys;
- Maintain identity persistence as keys are added, removed, or rotated;
- Resolve and communicate across various networks; and
- Control a DID document that expresses metadata, service endpoints, or other related information about the DID.
The DID spec was originally created by Respect Network (later acquired by Evernym) and presented at the Rebooting Web of Trust conference. It later moved to the Decentralized Identity Foundation (DIF), which was founded by uPort, Microsoft, Sovrin, Blockstack and many other companies with deep knowledge of identity and Web3. These organizations had differing needs and approaches but were all committed to the vision of a shared and interoperable model for self-sovereign identity. The DID spec was created to ensure efforts complemented each other and any application using DIDs had access to the whole ecosystem of users and capabilities, and nobody was locked into a single siloed approach.
Any product, service, or platform with ambitions to build a true user base and a desire to participate in and benefit from the global Web3 movement should be using DIDs. DIDs are the necessary minimum identity requirement for any application, service, or platform that wishes to serve users in any way beyond impersonal, on-chain buy/sell/transfer transactions. There are many implementations that are easy to implement.
DIDs alone are insufficient
Using a DID for identity means you can have interoperability in the future. It is the basic piece that should be built-in from the start. However, simply using DIDs does not give you cross-network interoperability or access to the full suite of user management and identity-related tools and patterns that are emerging and that will continue to emerge.
DIDs serve as the unique identifier for users and come with a bare minimum of information and capabilities required to be resilient, persistent, and interoperable. But this is not enough as many other capabilities and features used in your application may have their own “identity” needs beyond a basic user ID. For example:
- Databases with cryptographic access control need their own keys and key management
- DAOs and organizations need permissions delegation and membership links in a different way than users
- Different wallets, notification services, and verification services will have their own designs
- Users will bring various linked accounts, asset types, and preferences

With a good decentralized identity system, all of these permutations should fit together seamlessly. Aggregating user management related features around the user’s identity turns an identity into the single API for the entire suite of user functionality. Each feature simply plugs in as a module that speaks to the others.
For example, you don’t want to tie together user IDs, notification services, profile data, and cryptographic accounts one by one, the way that user tables and one-off integrations are managed today. With this approach, time and complexity grows rapidly — as new capabilities grow linearly, integrations and mappings to manage grows geometrically (Metcalfe’s Law). Instead, you want to have each new feature or capability tie to a user’s DID, making it easy to upgrade, replace or configure as you go.
The blueprint for a complete identity standard
DIDs form the basis for globally usable and interoperable identifiers but a true identity system and infrastructure must do much more than that.
A complete identity system builds upon the starting point of DIDs to make identity the easy, simple, and flexible integration point for all of an application’s user-related functionality.
A practical and seamless identity system should give any DID the power to manage, route to, and control a flexible and powerful graph of information and services about the user — regardless of where the information was initially generated and where it’s currently stored or hosted. And it should do this with basically no action required by the user and very little effort required by developers.
Five important properties of an interoperable identity standard
To provide the true promise of decentralized identity infrastructure, and do it in a practical way that meets you as a developer where you are, 5 core elements beyond DIDs and proprietary identity systems are needed:
1. Flexible, standard, DID-agnostic model (many networks → one identity)
Identity is much more than just DIDs. The promise of DIDs was to eliminate identity provider lock-in, however most DID-based identity systems are opinionated and require that users use their specific DID method. A strong identity infrastructure provides a complete identity-based capability model that is DID-agnostic, flexible, permissionless, and works across the worldwide web. This lets it support users, organizations, IoT devices, and almost any use case wherever they come from in the future.
2. Chain-agnostic, multi-key authentication (many keys → one identity)
For DIDs and their associated information to be interoperable across networks, wallets, and applications, they need to support a flexible multi-key authentication system that supports any key pair. A keychain model provides cross-chain interoperability while also adding resilience to the DID since the only way a user could lose control of a DID is if they simultaneously lose control of all their wallet keys at the same time.
3. Shared account metadata (e.g., portable profile and reputation)
For DIDs to be usable in the context of applications, they need to support the storage of various kinds of public account metadata such as profiles, social connections, or verifiable claims. Identity infrastructure should provide a standard framework for storing this kind of information, which can also be extended to support any other kind of account metadata.
It encourages standardization where useful to all, but does not force it where diversity is needed; and it makes extensions, branches and versions easily discoverable and linkable.
4. User-centric routing to external resources (e.g., rich data ecosystem)
A majority of data belonging to a DID is not account metadata, rather it’s the data generated as a user interacts with an application which may be stored anywhere on the internet, from servers to blockchains. This can be basic browsing data, user data, content, credentials about the user, reputation claims, or other game- or platform-specific data. This information is an important part of an identity, and in order for this data to be usable across applications, it needs to be associated to the DID to be discoverable by any application, regardless of where it exists and how it is stored.
5. On-chain account mappings (e.g., NFT or contract ownership)
Since most decentralized applications built on blockchains currently require users to interact with their application using a key pair account that lives on that specific chain, applications need a way to lookup a user’s blockchain account and resolve it to a DID. This allows the application to query public metadata about the user’s account, which is actually associated with a DID. Account links should provide these on-chain to DID mappings that can work for accounts or contracts that live on any blockchain or network.
A dynamic and interoperable identity graph
Together, these five capabilities call for infrastructure that lets applications, services, networks and users flexibly tie new identity-related information together. Rather than a single monolithic solution, what’s needed is reliable and distributed middleware for user-centric linking and routing of resources.
This is best achieved through a set of linked documents that together represent a complete identity as a graph of information. A graph that is globally available, distributed, censorship-resistant, and permissionless for any app, service or user.
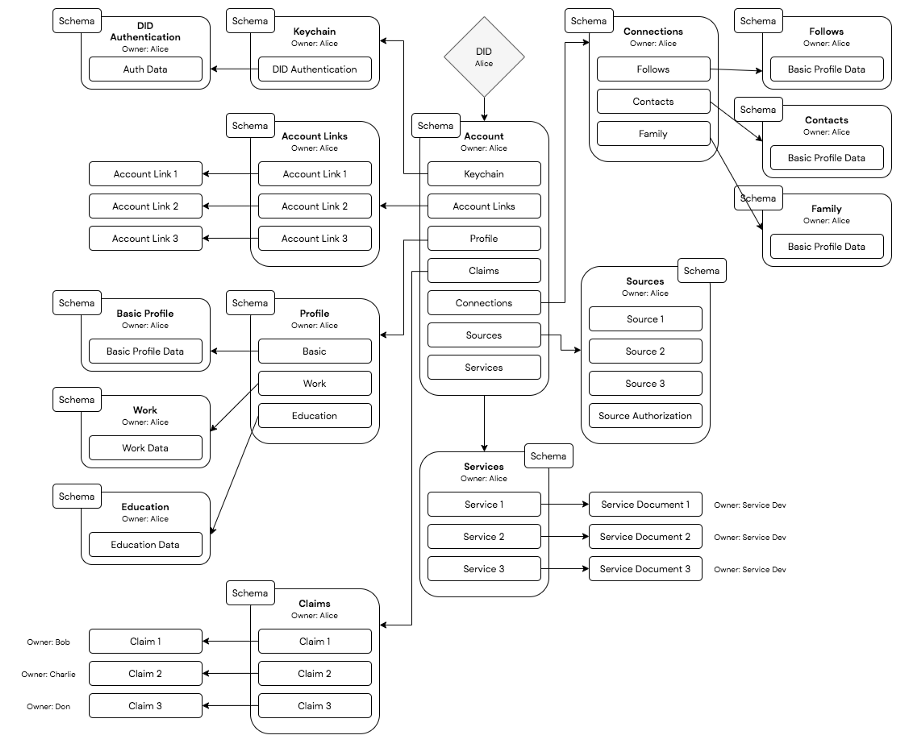
This graph extends any DID with a standard yet flexible account model, portable metadata storage, multi-key and privacy preserving authentication, and links to external resources located anywhere on the internet. It gives DIDs the ability to link to external resources such as application data and trusted services such as notifications or backup, offering a simple user-centric routing system for all kinds of resources related to an identity. The same system can be used to manage access controls, privacy policies, or preferences related to these off-chain resources.
With a flexible identity graph, users have the power to manage their identity and data with control and privacy, and apps have the power to tap into a rich ecosystem of identity data and capabilities without compromising their needs or stack.
This identity infrastructure paves the way to an ecosystem of linked and interoperable services and data. Identity infrastructure can make users, social graphs and services composable in the same way that blockchains make assets composable, and help Web3 products grow faster and easier together.
Get started building with decentralized identity
Implementations of interoperable identity
This identity model is being actively used by the Web3 community today. More and more projects are using DIDs (3ID, EthrDID, Ion), ensuring the most basic foundations of user-control and interoperability are met. A limited version of the linked graph model that extends DIDs with complete identity capabilities is in widespread use in the Ethereum ecosystem, via 3Box. More than 700 apps and 22,000 users have decentralized identity, profiles and linked databases so far.
Ceramic Network is being built to extend this DID-based identity graph capability to any network, key type, DID, resource type, or implementation. Ceramic is a permissionless network for storing verifiable, mutable, linked documents that is perfect for this graph of identity information. The identity routing protocol (IRP) is the first graph standard being built on Ceramic, with a testnet live now and a full implementation this fall.
Along with 3Box, many of the best projects in Web3 are contributing to make sure the IRP standard scales to their use case, goals and requirements. This includes wallets like Metamask and Magic, blockchains like Arweave and Filecoin, databases like OrbitDB, Sia and Textile, and communities and applications from across the space.
We’re adding new projects and perspectives every week, and would love to include yours. Real world identity is not static or rigid; it is dynamic, rich and full of many perspectives. Digital identity should be too.

Get started today
You don’t have to make big changes all at once. There are simple steps you can take to ensure you are building on a strong identity foundation and are set to have identity be an advantage rather than pain-point as you grow.
- Build DIDs into your application, which takes at most ~1 day. You can use 3ID from 3Box, a lightweight IPFS-based DID that will be natively built into Ceramic.
- Join us in the Ceramic discord to share your use case, give input to help shape the network and standards, or ask any questions you have. Or join our mailing list.
- Share or discuss on twitter with the global Web3 builder community. Our Web3 ecosystem will grow best if work together, and that starts with a solid foundation for interoperability.